MySQL 的查询语句~
查询语句的执行顺序
条件查询
- 按条件表达式筛选:条件运算符
> , < , = , != , >= , <= , <> - 按逻辑表达式筛选:逻辑运算符
&& || ! and or not
select 字段名 from 表名 where 字段 > 1200;
select 字段名 from 表名 where 字段 > 1200 and 字段 < 3000;
还有一些用来简化上面的关键字 between and , in , is null ,is not null
-- 查询员工编号在100到120之间的员工信息
select * from 表名 where id > 100 and id < 120;
-- 使用between and
select * from 表名 where id between 100 and 120;
-- 查询员工的工种编号是 123 或 321 或 456 的员工信息
select * from 表名 where id = 123 or id = 321 or = 456;
-- 使用 in
select * from 表名 where id in (123,321,456);
模糊查询
模糊查询的关键字:like
模糊查询使用的通配符
%:表示任意个字符_:表示一个字符 (如果要查找的字段本身带有_则使用转义符例:'_a\_%')
select 字段名 from 表名 where 字段 like '_a_b_c%';
查询结果排序
语法:
select 查询列表,
from 表
(where 筛选条件)
order by 排序列表(asc|desc) -- 默认是升序
- 可以支持单个字段,多个字段,表达式,函数,别名
order by子句一般是放在查询语句的最后面
使用例:
# 按年薪的高低显示员工的信息和年薪
select * , salary*12*(1+ifnull(提成,0)) as 年薪 from 表 order by 年薪 desc;
# 查询员工信息,先按工资排序,再按员工id排序
select * from 表 order by 工资,id desc;
对结果进行分组
语法:
select 分组函数 -- 这里只能使用分组函数,和用来分组的字段
from 表
[where 筛选条件]
group by 分组列表
[order by 排序列表(asc|desc)]
使用例:
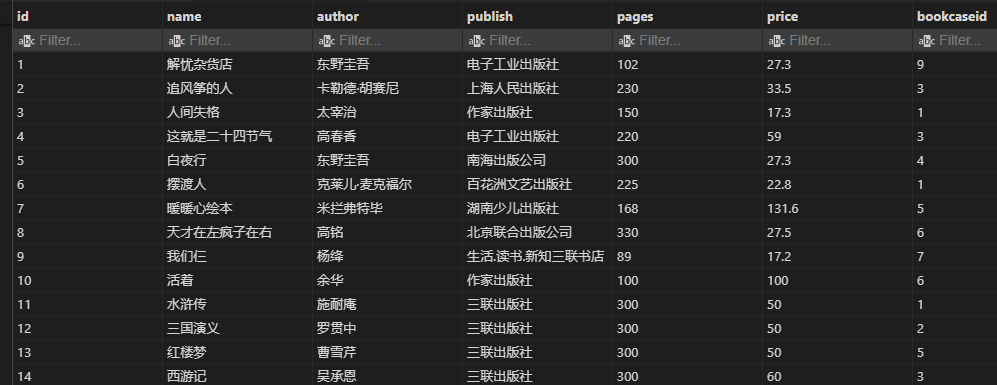
# 查询出版社里的最贵的书
select max(price) as '出版社里最贵的' ,publish
from book
group by publish
order by '出版社里最贵的' desc;
分组后的筛选
having 关键字是对 group by 之后的结果进行筛选
-- 查询哪个部门的员工数 > 2
-- 分步骤 1.查询每个部门的员工数 2.根据1的结果进行筛选
select count(*) as 员工数,部门
from 表
group by 部门
having 员工数 > 2;
连接查询
又称为多表查询,当查询的字段来自于多个表时,就会用到连接查询
select 查询列表
from 表1 别名 [连接类型]
join 表2 别名 on 连接条件
[where 筛选条件]
[group by 分组列表]
[having 筛选条件]
[order by 排序列表(asc|desc)]
- 内连接(inner join):取出两张表中匹配到的数据,匹配不到的不保留
- 外连接(outer join):取出连接表中匹配到的数据,匹配不到的也会保留,其值为NULL
内连接
又称为简单连接,或者自然连接,是一种常见的连接查询 内连接使用比较运算符,对两个表中的数据,进行比较,并列出与连接条件匹配的数据行,组合成新的记录。
在内连接查询中,只有满足条件的记录,才会出现在查询结果中
-- 语法格式
SELECT 查询字段 FROM 表1 [INNER] JOIN 表2 ON 表1.关系字段=表2.关系字段;
INNER JOIN 关键字用于连接两个表,其中 INNER 可以省略
内连接分为 等值连接 和 非等值连接
等值连接
- 多表等值连接的结果为多表的交集部分(珍珠项链的珍珠)
- n 表连接,至少需要 n-1 个连接条件
- 多表顺序没有要求
-- 查询员工名,部门名
select 员工名, 部门名
from 员工表 e
inner join 部门表 d
on e.id = d.id;
非等值连接
-- 工资位于 1000(low) 到 3000(higt) 的员工
select *
from 员工表 e
inner join 工资表 g
on e.工资 between g.low and g.higt;
外连接
以某一个表为主表,进行关联查询,不管能不能关联的上,主表的数据都会保留,关联不上的以 NULL 显示(用于查询一个表有,另一个表没有的记录)
通俗解释就是:先拿出主表的所有数据,然后到关联的那张表去找有没有符合关联条件的数据,如果有,正常显示,如果没有,显示为 NULL
外连接又分左外连接(left 左边的是主表),右外连接(right 右边是主表)
- 外连接的查询结果为主表中的所有记录
- 如果从表没有相匹配的则显示 null
- 外连接查询结果 = 内连接结果 + 主表中有而从表没有的记录
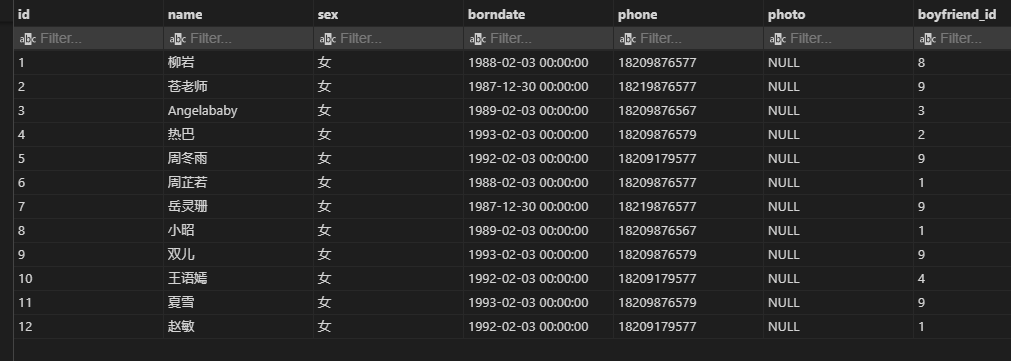
使用例:
女生表 g:
男生表 b:
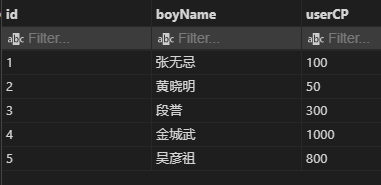
-- 找没有男朋友的女生
select g.*
from 女生表 g -- 主表
left outer join 男生表 b
on g.男朋友id=b.id
where b.id is null;
结果:

子查询
出现在其他语句中的 select 语句,称为子查询或内查询(所以外部的查询语句称为主查询或外查询)
select 名字
from 员工表
where 部门id in
(
select 部门id
from 部门表
where 位置id=1700
)
limit 关键字的妙用~
查询数据时,可能会查询出很多的记录。而用户需要的记录可能只是很少的一部分。这样就需要来限制查询结果的数量。Limit 是 MySQL 中的一个特殊关键字。Limit 子句可以对查询结果的记录条数进行限定,控制它输出的行数。
分页查询
-- 语法:
select 查询列表
from 表1 别名 [连接类型]
[join type] join 表2 别名 on 连接条件
[where 筛选条件]
[group by 分组列表]
[having 筛选条件]
[order by 排序列表(asc|desc)]
limit offset , size
它的两个参数:
- offset:要显示的条目起始索引(从0开始)
- size:要显示的条目个数
限制结果数量
-- m:表示查询多少条记录。
LIMIT m;
查询用户信息表(tb_user),按照 user_id 编号进行升序排列,显示前 5条记录。
SELECT * FROM tb_user
ORDER BY user_id
LIMIT 5
这样它就会查询出前五条数据,而到了 MyBatis 这里也可以通过它避免出现多条结果
@Repository("brandMapper")
public interface BrandMapper extends Mapper<Brand> {
/**
* 根据id查询品牌信息,这里通过 limit 关键字限制结果的数量~
*
* @param id
* @return
*/
@Select("select * from tb_brand where id = #{id} limit 1")
Brand findById(Integer id);
}
联合查询
应用场景:需要将多条查询语句的结果合并成一个结果
查询语句1
union
查询语句2
union
查询语句3
union